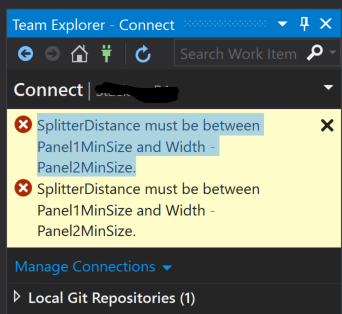
SplitterDistance must be between Panel1MinSize and Width – Panel2MinSize
On the first attempt to connect to the Visual Studio Professional 2015’s Team Explorer on a brand new virtual development machine for Dynamics 365 for Finance many of us have been taken by surprize by the notorious “SplitterDistance must be between Panel1MinSize and Width – Panel2MinSize.” error message.
The Internet has a few tips https://stackoverflow.com/questions/33845414/… more or less useful, and the true reason is this: VS 2015 UI does not manage the high resolution well. Most of us will use a full-screen RDP connection to the virtual machine, Windows takes the native resolution of your notebook by default, passes this to Visual Studio and this leads to the said error message. The full HD resolution of 1920 x 1080 already means trouble.
The solution is simple:
- Sign off from the VM.
- Change the RDP connection settings from the fullscreen to 1024×768.
- Sign on to the VM.
- Start Visual Studio and connect to the Team Explorer for the first time.
- Close Visual Studio and let it save your preferences.
Next time, the error message will not occur even when connecting to another DevOps server.